2023. 3. 15. 16:33ㆍSQLD 정리
성능 데이터 모델링
- 데이터베이스의 성능 향상을 위해 분석/설계 단계부터 성능과 관련된 사항이 데이터 모델링에 반영되도록 하는 것
- 데이터의 증가가 빠를수록 성능 개선 비용이 증가함
- 설계 단계부터 고려할 경우 비용 최소화가 가능함
- 한 테이블에 너무 많은 칼럼이 존재하여 로우체이닝이 발생하는 등 조회성능 저하가 발생한다면 트랜잭션이 접근하는 칼럼유형을 분석해 테이블을 분리하면, 디스크 I/O가 줄어서 성능이 향상 될 수 있다.
- WHERE 문을 통해 조회를 할 때 자주 사용되는 PK순으로 순서를 변경하고 인덱스를 생성하는 것이 성능에 유리할 수 있 다.
EX) WHERE 지역명 = '서울' AND 출시일 BETWEEN '20221111' AND '202311'
>>> 앞쪽에 위치한 속성의 값이 가급적 '=', 최소한 범위를 나타내는 'BETWEEN', '<', '>'가 들어와야 인덱스를 사용할 수 있다.
- 트랜잭션 통합/개별 처리
>데이터 전체를 일괄 처리하는데 테이블이 개별로 관리되면 오히려 연산량이 늘어나고 데이터를 개별로 처리하는데 테 이블은 하나로 통합되어 있으면 성능이 저하될 수 있다.
성능 데이터 모델링 순서
1. 데이터 모델링 시 정규화 정확히 수행
2. 데이터베이스 용량 산정
3. 데이터베이스에 발생하는 트랜잭션 유형 파악
4. 용량과 트랜잭션 유형에 따라 반정규화 수행
5. 이력모델, PK/FK 조정, 슈퍼타입/서브타입 조정을 수행함
정규화
- 데이터를 분해하는 과정
- 데이터 중복 최소화, 유연성을 가지며 젼경을 최소화, 데이터가 일관될 수 있도록 하는 방법
- 제 1~5 정규화가 있고, 주로 1~3 정규화까지 수행
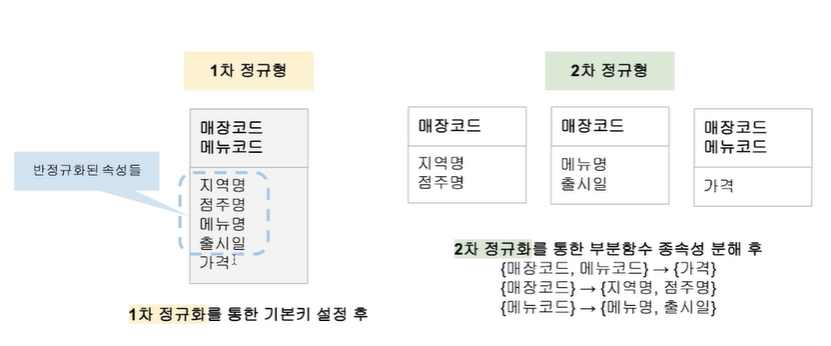
제 1 정규화
- 기본키를 설정하는 과정
- 속성의 원자성과 엔티티의 유일성을 확보
- 모든 속성이 식별자에 종속되어야 함
참고)
종속된다는 말은 X가 변하면 Y가 변하는 경우 Y는 X에 함수적 종속된다고 할 수 있다.
제 2 정규화
- 기본키가 2개 이상으로 구성될 경우 수행함
- 모든 속성이 식별자에 종속되어야 하며, 아니면 분해해야 한다.
- 부분 함수 종속을 분해함
- 주식별자 중 일부로부터 독립하여 1:M의 관계로 재설계
제 3 정규화
- 기본키 외에 컬럼간 종속성을 제거함
- '이행 함수 종속성' 제거

반정규화
- 정규화를 했을 때 성능이 더욱 악화될 경우, 데이터 중복을 허용하고 조인을 줄여서 성능을 향상시키는 방법
- 반정규화 기법
> 칼럼추가 : 중복칼럼 추가, 파생칼럼 추가, 이력 테이블 칼럼추가, PK에 의한 칼럼 추가
EX) 중복칼럼 추가
A테이블에 있는 a, b 정보를 조회할 때 C테이블의 c 정보와 D테이블의 d 정보를 늘 함께 조회하면 과도한 조인을 줄 이기 위해 A테이블에 c,d컬럼을 추가하여 조회 성능을 향상
EX) 파생칼럼 추가
여러 테이블을 JOIN해서 얻을 수 있는 정보값이 자주 사용되면 미리 계산된 칼럼을 추가해준다.
> 테이블 병합/분할/추가
1) 테이블 병합 : 1대1 관계 테이블 병합, 1:M 관계 테이블 병합, 슈펴/서브타입 테이블 병합
2) 테이블 분할 - 수직분할, 수평분할
3) 테이블 추가 - 중복테이블, 통계테이블, 이력테이블, 부분테이블
출저) [SQLD 자격증] 8만명이 유튜브에서 검증한 메타코드M의 대표강의 | Udemy
'SQLD 정리' 카테고리의 다른 글
| SQL - 데이터 모델링, 데이터의 구성(엔티티, 속성, 인스턴스), 도메인, ERD, 식별자 (0) | 2023.03.15 |
|---|---|
| SQL - PL/SQL, 분산 데이터베이스 (0) | 2023.03.15 |
| SQL - 옵티마이저, INDEX (0) | 2023.03.14 |
| SQL - 윈도우함수, 파티션 (1) | 2023.03.14 |
| SQL - 계층형 조회 (0) | 2023.03.14 |